第1回のコラムにて、S/4HANAへのシステムコンバージョンにおいてアセスメントが重要かつ膨大な調査を必要とし、とりわけUnicode化対応については、地道な調査が必要となることをご説明しました。
第2回では、Unicode化による影響はどのようなものか具体的な解説と、Unicode化対応の調査工数を削減するための当社の取組をご紹介します。
Unicode化により、Non-Unicode環境ではプログラムで使用できた命令が特定の条件で使用できなくなるケースがあります。
一方で、Unicode環境においても引き続きプログラムで利用可能な命令であるものの、Non-Unicode環境とは異なる挙動となるものがあります。
SAPの標準ツール(UC Check)によって検出できるのは、ほぼ前者のケースとなり、後者が地道な調査により影響箇所を特定するものとなります。
ここで、Unicode化により挙動の変わる一例を紹介します。
Unicode化によって、プログラムの中で文字をカウントする単位が「バイト」から「文字数」に変更されます。
Non-Unicode環境のプログラムでは、半角文字は1バイト、全角文字は2バイトとカウントしていましたが、Unicode環境では半角文字は1文字、全角文字は1文字とカウントするため全角文字のカウントに差異が生じます。

プログラムでは基準となる位置から、ある位置までを表す場合に、オフセットという表現を使いますが、上記の差異によりオフセットを使用した処理に影響が出ます。 例えば、Non-Unicode環境で作成されたプログラムで、オフセットを行い7バイト目から住所情報を出力する命令が組み込まれていた場合、そのままUnicode環境で実行すると7文字目から住所情報が出力され、出力結果に差異が生じてしまいます。
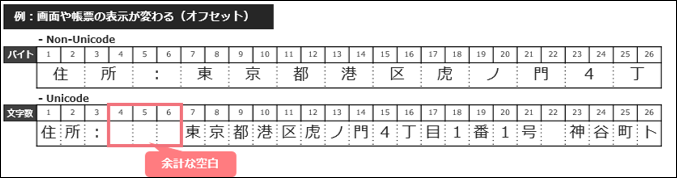
通常、このような事象については、地道なプログラムソースレベルの調査が必要となり、調査で検出ができなかった場合は、後続のテストで影響箇所を特定することになります。
また、テストにおいてもデータパターンによっては検知できないケースがあるため、オフセットを使用した処理の調査が重要なポイントとなります。
当社の提供しているSAPアセスメント(Unicode)ツールでは、先ほど例に挙げたようなUC Checkでは検知できない影響の可能性がある箇所をプログラムソースコードレベルで特定します。
具体的なチェックとして、お客様環境にてアドオン開発されたプログラムソースを読み込み、オフセットを行う処理や関数の他、オフセット以外の影響のある関数を特定します。
このツールにより、Unicode化における調査が自動化され、大幅な工数削減、調査内容の品質向上につなげます。
【SAPアセスメント(Unicode)ツールのチェック内容】
| カテゴリ | チェック項目 |
|---|---|
| オフセット | 文字列操作でのオフセット |
| WHERE文の列/条件値に対するオフセット | |
| IF・CASE・CHECK・WHILE文の条件式でオフセット | |
| CLEAR文でのオフセット | |
| READ TABLE…WITH KEYに対するオフセット | |
|
WRITE 変数 TO 内部テーブル に対するオフセット |
|
| SORT命令のソートキーに対するオフセット | |
| テストその他 | 16進符号使用 |
| 変数の文字数取得 | |
| 変数内文字移動 | |
| 文字項目右揃え/中央揃え | |
| 文字項目右揃え/中央揃え(オフセット指定) | |
| 文字列の格納・出力 |
ここからは、実際に当社ツールを使用したアセスメントの流れについてご説明します。
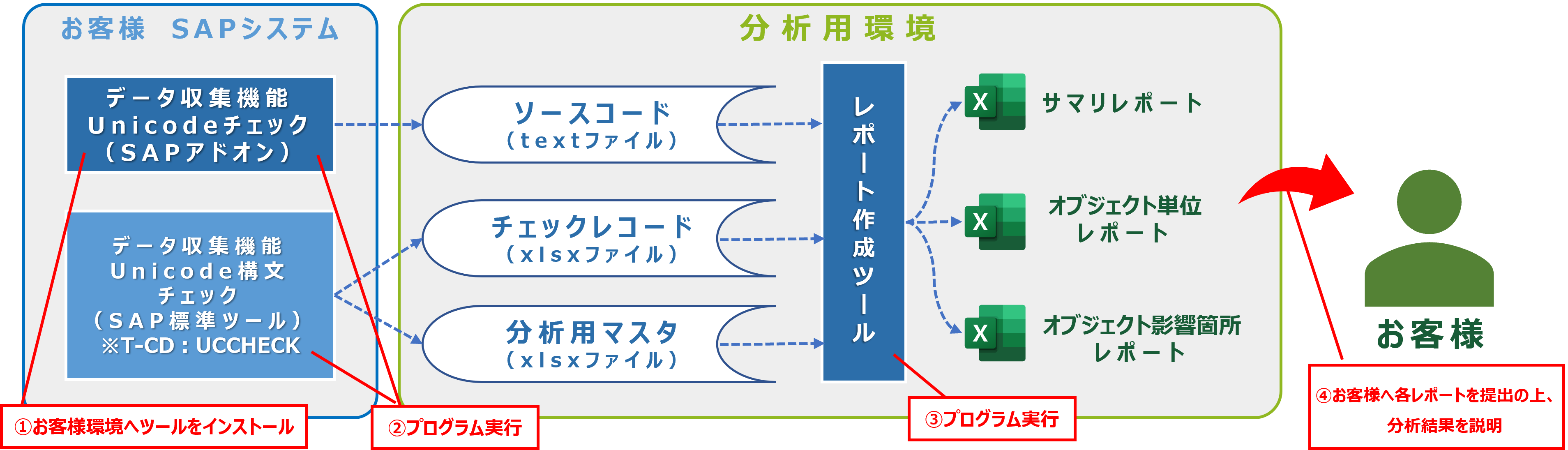
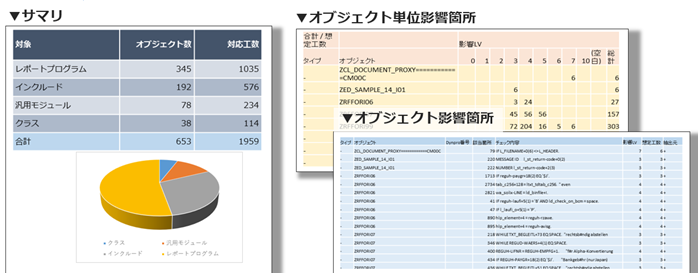
上記の通り、Unicode化に特化した当社のSAPアセスメント(Unicode)ツールを使用する事により、SAP標準ツールだけでは特定が困難なプログラムソース毎の影響箇所を特定し、3種類のレポートによってUnicode化による影響レベル、必要な作業内容・工数を把握する事が可能となります。
S/4HANAへのコンバージョンと合わせてUnicode化のアセスメントを行う場合や、Unicode対応に課題をお持ちのお客様は是非、当社へお問い合わせください。
CTCシステムマネジメントコラム
CTCシステムマネジメントコラムでは、ITシステム運用の最新動向に関する特集・コラムがご覧いただけます。


