システム運用
第1回目でお話ししました、便利なOSSの監視ツールZabbixを使いこなして頂けるよう過去の経験から気づいた留意点や改善ポイントについてコラム形式で解説しています。
今回は①ログ監視の仕様に関するお話を書きたいと思います。
1.ログ監視検知・収集の仕様
2.ログファイル読込みの仕様
3.Zabbixログ監視をうまく使いこなし運用するために
Zabbix も他の監視ツールと同じくログ監視機能を有しています。
ログファイルに書き込まれる「error」などのキーワードをZabbixエージェントが定期的にチェックして、対象文字列を発見すると障害イベントを通知するというものです。
ログ監視に限らずですが、Zabbixの監視設定は大きく分けてアイテムとトリガーという2つの設定で行います。アイテムは監視項目を設定し、トリガーは障害判定設定を行います。アイテムという単位で監視対象(CPUの使用率やプロセス名など)を決め、そのステータスデータを一定の監視間隔で収集します。
ログ監視の為のアイテムの監視対象はログファイルそのものとなり、ファイルパスなどを使ってその設定を行います。
※今回はログ監視の検知・収集のお話の為、トリガーの説明は割愛します。
ログ監視のアイテム設定は概ね以下の様に設定します。
名前 :ログ監視_delated (任意。分かりやすければなんでも良い)
キー :log[“/var/log/Zabbix/Zabbix_sever.log”,”delated”]
タイプ:Zabbixエージェント(アクティブ)
監視間隔(秒):60
・・・ etc
※タイプは、Zabbixエージェントの動作に関する設定です。ログ監視の場合は、Zabbixエージェント(アクティブ)を設定する場合が多いです。
ログ監視の基本的な動作として、第一引数で監視対象ファイルパスを指定し、そのファイルに書き込まれた文字列を監視するのですが、regexp未指定でも監視動作を開始させる事は可能です。
未指定の場合、書き込まれたログすべてをサーバへ送り、ZabbixサーバのDBのヒストリーテーブルに保管するという動きをします。
これによりどうなるか?気を付けて欲しい内容を、具体的に図を追って説明します。
下図をご参照いただきつつお読みください。
①Zabbixエージェントがログを収集
ログ監視アイテムの設定に基づき、指定されたパスの対象ログを読み込みます。
Zabbixは前回どこまで読んだかを記録しており常に新しく書き込まれたログを監視し、指定したキーワード(これが第二引数のregexp です)が該当する行がZabbixエージェントにより取り込まれます。この図の場合はログファイルに記載される3行のうち、“deleted”が含まれる3行目のログが該当します。
②ZabbixエージェントがログをZabbixサーバに転送
取りこんだログがZabbixエージェントからZabbixサーバに送られます。
③ZabbixサーバがログをDBに保管
Zabbixサーバは転送されたログをそれがどのホストのどのアイテムから取得されたログか分かる形でDB(ヒストリテーブル)に書き込みます。
④条件に合致し障害と検知された場合、管理者へ通知
アイテムの連携するトリガーが指定された条件にしたがい障害判定を行います。
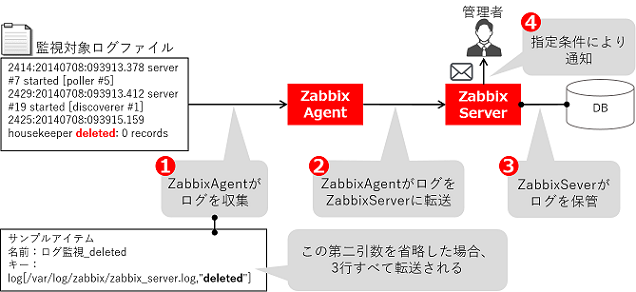
ログ監視による監視対象データが保管される仕組みは概ね上記(図1)の通りです。
保存期間にもよりますがDBの容量枯渇を防ぐ為、監視対象キーワードはなるべく検知させたい文字列を事前に調査し設定を行う設計にするのが良いと思います。
稀にZabbixでログサーバの役割をさせようとする方がいらっしゃいますが、syslogサーバとしてログ転送に最適化されている訳ではないですし、Zabbix のDBにはリソース監視などその他の監視項目の履歴データも保存します。そのため、パフォーマンスにも影響しますのでログ保管の為にZabbixを使う事はお奨めしません。
ご覧いただいた例(図1)ですと、logキーに第二引数を指定しフィルタする事で、3行分(174バイト)書き込まれたデータからフィルタされた1行分(55バイト)のデータだけが保管される事を示しています。
また、ログ監視に関するお問合せの中で特徴的なものに 「過去の障害を検知してしまう」 というものがあります。
例えば、一か月前の障害内容が最近通知されてしまうといった内容です。
実際には、既に過去に一度取り込んだログが再度トリガーの条件判定対象に該当してしまいアラートが通知されてしまう、ということが発生しているのです。
前章でご説明しましたが、Zabbixは監視間隔の度に対象ファイルを読み込んで検索対象文字列が書き込まれたか監視しています。
ログファイルにはシステムの様々な書き込みが行われますが、Zabbixは前回の監視でどこまで読んだかという記録を対象ファイルのゼロポジションからのオフセット(読み込んだサイズ)の形で保存しておく為、どこまで読んだかが継続して追えてログ監視できる仕組みになっています。
以下の図の様にどこまで読んだかのファイルサイズ(lastlogsize)が使用されるため、これが0でクリアされると対象ファイルは先頭から読み直しになり、動きとしては過去のエラーを再度読むと言う事自体は当然の仕様となります。
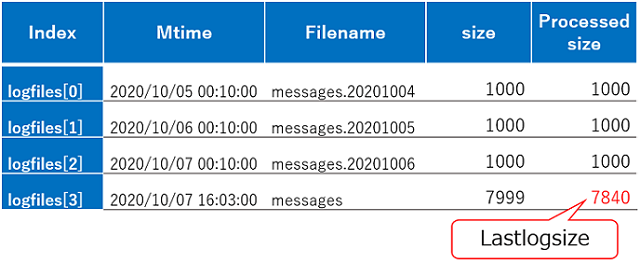
上記の表(図2)は/var/log/ ディレクトリ以下で条件に合致したファイルが4ファイル存在し、指定した文字列を監視している例です。前回からのlastlogsize が7840 バイトの時、messages の7841バイト目から読み込む形になります。
ローテーションなどの理由から監視対象ログファイルがファイルとして変更された場合、Zabbixはi-node等でファイルが作成された事を判別し別途処理を行う為、読み直しは発生しません。
今回は、ログ監視アイテム設定の仕様からデータ保存量肥大の可能性がある事とログ監視動作の仕様からログファイルを頭から読み直してしまう可能性がある事について述べました。
いずれも設定前/発生前、事前に知っておくと良い内容と考え取り上げました。
そもそも、監視システムのデータ保存量を気にしないで保存し放題な環境はあまりないと思います。
ディスク残量が逼迫してからですと手の打ち様も少なくなってしまうため、ログ監視アイテムのデータ取得の幅は広く持たせたい事もあると思いますが、最小限に抑える事を知った上でバランスとる設定をすると良いと考えます。
また、ログ監視がどこまで行われていたかの記録の0クリアがいざ発生すると「Zabbixが障害をおこしている」と言う誤った認識からの問合せを受ける事があります。
障害調査の際は事実に則した状況調査が必要な為、憶測で話が進みますと思わぬ調査の時間ロスを発生させます。
この様な仕様があると知っておくだけでも、その場に当たって慌てる事がない点、監視対象ファイルを安易に書き換えたりしないと言った点について気を付ける事ができると思い、この様な話をしました。
次回は、「②SNMP監視に関しての留意点」についてお話しします。引き続きお楽しみいただけると幸いです。

<著者>
三宅 徹芳
<経歴>
プログラマ ⇒ CE ⇒ オペレータ ⇒ 運用管理 ⇒ SE …と、職種を変えつつ活動。現在はOSSの運用管理ツールの導入と保守を主業務にしており、効果的な使い方の研究や外部研修で成果発表などしています。
CTCシステムマネジメントコラム
CTCシステムマネジメントコラムでは、ITシステム運用の最新動向に関する特集・コラムがご覧いただけます。





